
인공지능 기술이 발전함에 따라, 현실 세계의 문제 상황에 인공지능 모델을 활용하는 사례가 많아지고 있다. 이때, 인공지능 모델은 학습 과정에서 보지 못한 데이터를 마주하는 경우가 많다. 그렇기에 현업에 투입된 인공지능 모델은, 자신이 알지 못하는 데이터에 대해서도 합리적으로 추론할 수 있는 능력을 갖추어야만 한다. 사실상 모델이 학습된 데이터 너머의 데이터에서 얼마나 잘 일반화(Generalization)되는지 여부에 따라, 현업에서 모델이 얼마나 유용한지가 결정된다고 할 수 있다.
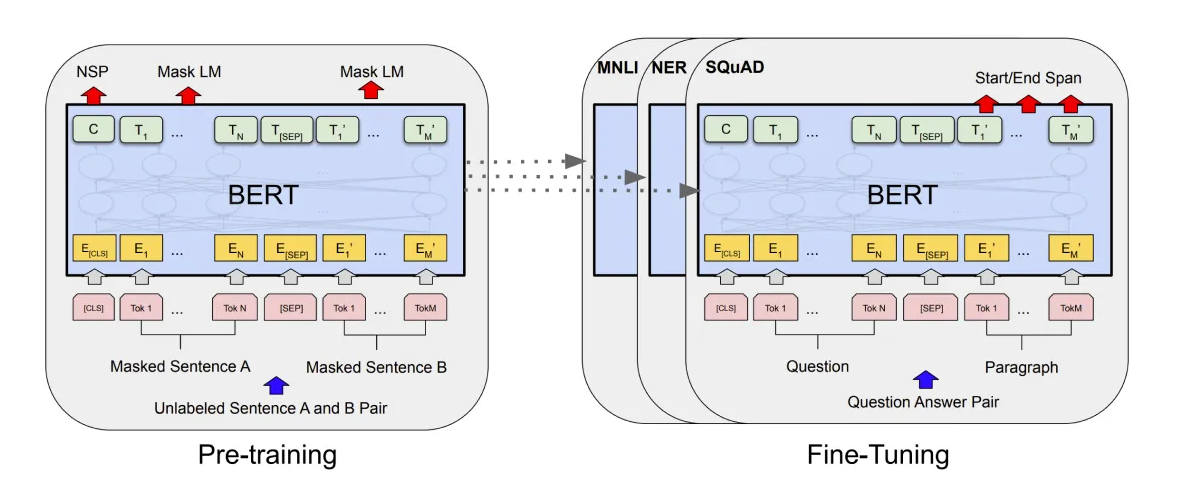
모델의 일반화 성능을 높이는 간단한 방법은, 최대한 다양한 학습 데이터를 제공하는 것이다. 이 때문에 최근에는 거대한 데이터로 선학습된(Pre-trained) 모델을 미리 만들어 두고, 풀어야 할 문제 데이터에 모델을 추가 학습(Fine-Tuning)시키는 2단계 과정이 일반적으로 사용되고 있습니다. 다양한 상황에 사용 가능한 특성 때문에, 이러한 선학습 모델들은 흔히 기반 모델(Foundation Model, FM)이라고 말합니다.
파운데이션 모델(Foudation Model)이란 ?
파운데이션 모델 (Foudation Model)이란 다양한 분야의 서비스에 적용할 수 있도록 개발되고 학습된 다목적 모델을 일컫는다. 그 이름처럼 AI서비스의 기반(Foundation)역할을 한다. 엔디비아에 따르면, ‘산더미 같은 원시 데이터에서 비지도 학습을 통해 훈련된 AI 신경망’이 파운데이션 모델의 정의이며, 광범위한 이용가능성이 특징이다.
파운데이션 모델의 특징
대규모 데이터셋과 모델 : 파운데이션 모델은 방대한 양의 데이터로 사전 학습된다. 이 데이터는 다양한 출처에서 수집된 텍스트, 이미지, 오디오 등 여러 유형의 데이터를 포함할 수 있다. 모델 자체도 대규모로 설계되며, 수억 개에서 수천억 개의 파라미터를 가질 수 있다.

범용성 : 파운데이션 모델들은 하나의 특정한 작업에 맞춰 설계되지 않고, 여러 작업에 적용될 수 있는 범용적인 특성을 학습한다. 파운데이션 모델은 사전 학습에서 얻은 지식을 특정 작업에 전이(transfer)할 수 있다. 이를 통해 새로운 작업에서 적은 양의 데이터와 짧은 학습 시간으로도 높은 성능을 달성할 수 있다. 또한 사전 학습 후, 다양한 다운스트림 작업에 맞춰 파인튜닝(Fine-Tuning)할 수 있다. 파운데이션 모델의 핵심 특징은 광범위한 적용 가능성이다. 단일 작업을 위해 설계된 것이 아니라 다양한 유형의 데이터를 이해하고 생성할 수 있으므로 다양한 애플리케이션을 위한 다용도 도구가 될 수 있다.

모듈성: 파운데이션 모델은 다양한 애플리케이션에 모듈식으로 적용할 수 있습니다. 예를 들어, NLP 분야의 GPT-3는 대화형 AI, 텍스트 생성, 번역 등 여러 작업에 사용될 수 있다.
파운데이션 모델의 작동 방식
사전 학습(Pre-Training): 모델은 대규모의 비지도 학습 데이터를 사용하여 사전 학습된다. 이 과정에서 모델은 데이터의 일반적인 패턴, 구조, 상관관계 등을 학습한다. 예를 들어, 텍스트 기반 파운데이션 모델은 인터넷에서 수집한 대규모 텍스트 코퍼스를 통해 언어의 문법, 의미, 상식 등을 학습한다.
파인튜닝(Fine-Tuning): 사전 학습된 모델을 특정한 작업이나 도메인에 맞게 추가로 학습시킨다. 이때, 적은 양의 레이블된 데이터가 사용된다. 파인튜닝 과정에서는 모델이 특정 작업의 특성을 학습하여 해당 작업에서의 성능을 최적화한다.
응용: 파운데이션 모델은 다양한 응용 분야에 적용될 수 있다. 각 응용 분야에 맞게 파인튜닝된 모델은 구체적인 작업을 수행하게 된다.
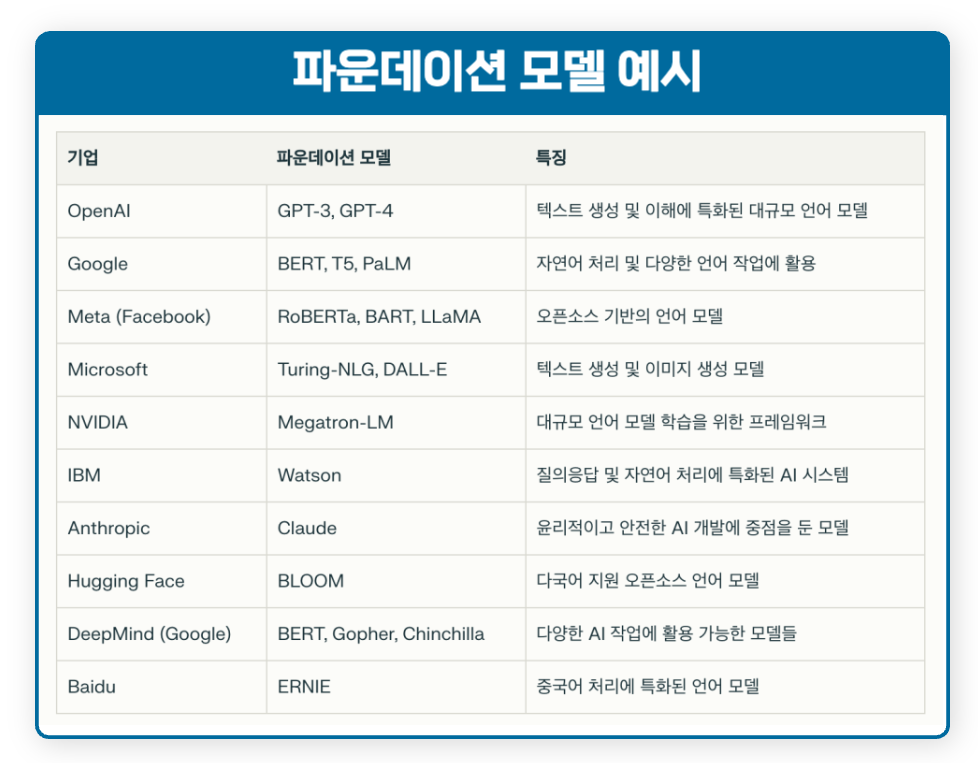
파운데이션 모델의 예시
파운데이션 모델의 초기 예는 구글의 BERT및 오픈AI의 "GPT-n" 시리즈와 같은 언어 모델(LM)이었다. 텍스트 외에도 이미지용 DALL-E 및 플라밍고, 음악용 뮤직젠(MusicGen), 로봇 제어용 RT-2 등 다양한 양식에 걸쳐 기반 모델이 개발되었다.
파운데이션 모델의 장점
모델 성능/정확성: 파운데이션 모델은 조직이 수개월 또는 수년간의 노력을 통해 구축할 수 있는 높은 수준의 정확성을 기본으로 제공한다.
효율성 : 머신 러닝 모델을 학습시키는 데 오랜 시간이 걸릴 수 있으며, 많은 리소스가 필요하다. 파운데이션 모델은 기본적으로 사전에 학습되므로 조직은 미세 조정을 통해 맞춤형 결과를 얻을 수 있습니다. 또한 파운데이션 모델은 조직이 데이터 사이언스 리소스에 막대한 투자를 하지 않아도 AI/ML을 활용할 수 있는 방법을 제공한다.
비용 관리: 파운데이션 모델을 사용하면 초기 학습에 필요한 값비싼 하드웨어를 사용할 필요가 줄어든다. 물론 최종 모델을 제공하고 미세 조정하는 데 비용이 들긴 하지만, 이러한 비용은 파운데이션 모델 자체를 학습시키는 데 필요한 비용에 비하면 일부분에 불과하다.
범용성 및 유연성 : 다양한 작업에 적용할 수 있는 범용적인 특성을 지녀, 여러 도메인에서 활용될 수 있다.
파운데이션 모델의 문제점
비용 : 파운데이션 모델은 개발, 학습, 배포하기 위해 많은 리소스를 필요로 한다. 초기에 파운데이션 모델을 학습시키는 단계에서는 방대한 양의 일반 데이터가 필요하며, 방대한 수의 GPU를 사용하고, 머신 러닝 엔지니어와 데이터 사이언티스트 그룹이 필요하기도 하다.
프라이버시와 보안 : 파운데이션 모델에는 많은 정보에 대한 액세스가 필요하며, 때로는 그러한 정보에 고객 정보나 독점 비즈니스 데이터가 포함되기도 한다. 이는 제3사 공급업체가 모델을 배포하거나 모델에 액세스하는 경우에 특히 주의해야 하는 부분이다.
정확성과 편향 : 파운데이션 모델이 통계적으로 편향된 데이터로 학습하거나 모집단을 정확히 대표하지 않는 경우 출력에 결함이 있을 수 있다. 안타깝게도 사람의 편견이 인공지능에 전달되어 차별적인 알고리즘과 편향 출력에 대한 위험을 초래할 때가 많다.